What is RAG (retrieval-augmented generation), and how does it work?
RAG makes an LLM answer from your data instead of only its training. Before the model writes, a retrieval step finds the most relevant passages and adds them to the prompt — so the answer is grounded in real, current facts.
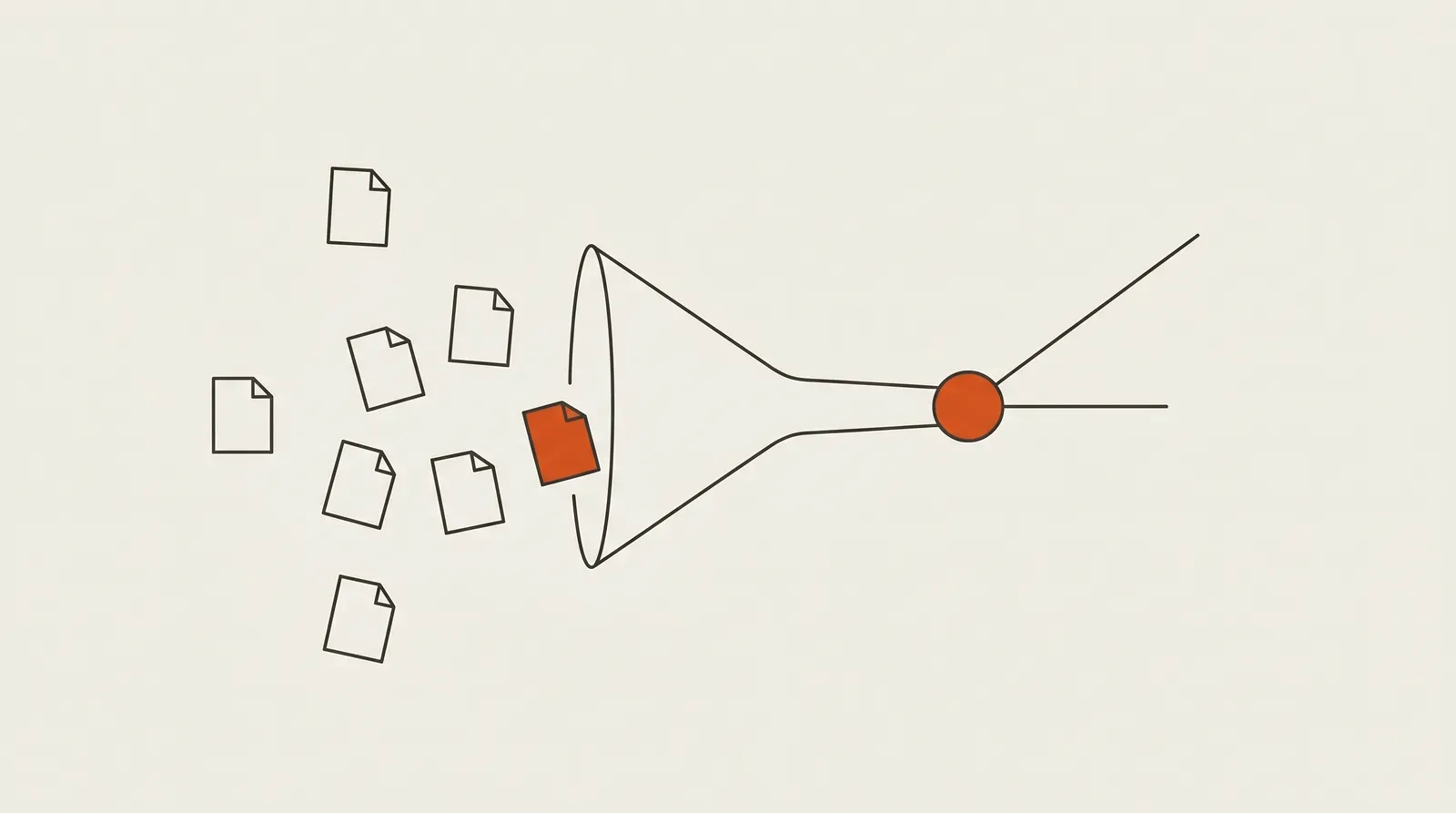
RAG — retrieval-augmented generation — is a way to make a large language model answer from your data instead of only what it learned in training. Before the model writes a word, a retrieval step searches an external knowledge base for the passages most relevant to the question and injects them into the prompt. The model then answers grounded in those real, current facts.
It is one of the most useful patterns in applied AI, because it fixes the two biggest problems with using an LLM on its own: it does not know your private information, and it confidently makes things up. RAG addresses both without the cost of retraining the model. Here is how it actually works.
What problem RAG solves
A language model's knowledge is frozen at the moment its training ended, and it only ever saw public data. Ask it about your internal policies, last week's prices, or a customer's account, and it has two options: admit it does not know, or — far more often — invent a plausible-sounding answer. That second behavior, hallucination, is what makes a raw LLM risky for real work.
RAG changes the task from "recall an answer from memory" to "answer using these specific documents I am handing you." The model stops guessing and starts reading. The term comes from a 2020 paper by Meta's AI research team, "Retrieval-Augmented Generation for Knowledge-Intensive Tasks," and it has become the default way to put company knowledge behind an LLM.
How RAG works, step by step
At the highest level the flow is: Query → Retriever → relevant context → LLM → grounded answer. Under that simple line are two distinct pipelines — one that runs ahead of time, and one that runs when a user asks something.
Phase 1 — ingestion (offline)
Before anyone asks a question, you prepare your knowledge so it can be searched by meaning, not just keywords:
- Chunk your documents into passages — a few sentences to a few paragraphs each. Chunking matters: too big and a passage mixes unrelated ideas; too small and it loses context.
- Embed each chunk with an embedding model, which turns the text into a dense vector — a list of numbers that captures the passage's meaning. Texts about similar things end up with similar vectors.
- Store those vectors in a vector database (or vector index), so they can be searched quickly.
This phase is run once up front, and re-run whenever your documents change — which is how a RAG system stays current.
Phase 2 — retrieval and generation (at query time)
When a user asks a question, the live pipeline runs:
- Embed the query with the same embedding model, turning the question into a vector.
- Search the vector database for the chunks whose vectors are closest to the query's — this is semantic, or "vector," search. It finds passages that mean the same thing, even if they share no exact words. You keep the top handful (the "top-k").
- Augment the prompt by placing those retrieved chunks into the context alongside the user's question.
- Generate — the LLM reads the question and the supplied passages, and writes an answer grounded in them, ideally citing which passage each claim came from.
The model never had to memorize your data. It just had to read the right page at the right moment.
A plain-English analogy
A raw LLM answering from memory is a student taking a closed-book exam — fluent, fast, and liable to bluff on anything it half-remembers. RAG turns it into an open-book exam: the student still has to understand the question and write the answer, but now the relevant pages are open in front of them. The reasoning is the model's; the facts come from your book.
A concrete example
Say an employee asks an internal assistant: "How many vacation days do I have left, and what's the carry-over policy?"
Without RAG, the model answers from training — it has never seen your HR policy, so it invents a plausible-sounding number and a generic policy. Confidently wrong.
With RAG, the flow is different. The question is embedded and used to search your indexed HR documents. Retrieval returns two chunks: the carry-over section of the leave policy, and (via a tool or pre-fetched record) the employee's current balance. Those chunks go into the prompt, and the model answers: "You have 12 days remaining. Per the leave policy, up to 5 unused days carry into next year; the rest expire on December 31" — grounded in the actual documents, and able to cite them. Same model, completely different reliability, because it answered from the right pages instead of from memory.
Why RAG beats fine-tuning for facts
People often ask whether they should instead fine-tune a model on their data. For pure knowledge, RAG usually wins on three counts: freshness (update the index in minutes instead of retraining), attribution (you can show the source passage behind every answer), and cost (no expensive training runs). Fine-tuning is the better tool for changing a model's behavior — its tone, format, or decision style — not for teaching it facts. The two are complementary, and we cover the full trade-off in RAG vs fine-tuning.
Where RAG breaks (and what to watch)
The most important thing to know about RAG is where it fails: most RAG failures are retrieval failures, not generation failures. If the retrieval step hands the model the wrong passages — because of bad chunking, a weak embedding model, or simply pulling ten chunks where only three are relevant — the model is set up to fail. It will faithfully answer from poor context, producing confident, well-written, wrong answers. Garbage retrieved is garbage out.
That is why serious RAG work measures retrieval quality first, separately from the final answer, before tuning a single prompt. If you are building or debugging a RAG system, start there — our guide to evaluating a RAG system walks through the exact metrics. Grounding the model in good context is also the single biggest lever for reducing hallucinations in any LLM feature.
When RAG is not the answer
RAG is the default for grounding a model in facts, but it is not a universal fix:
- When the problem is behavior, not knowledge. If the model knows the facts but answers in the wrong tone, format, or style, retrieval will not help — that is a job for fine-tuning. See RAG vs fine-tuning.
- When the knowledge fits in the prompt. If your entire reference material is a page or two, just put it in the context directly; you do not need a retrieval pipeline.
- When the task is reasoning, not recall. RAG supplies facts; it does not make a model better at math or multi-step logic.
The short version
RAG is the bridge between a general-purpose language model and your specific, private, changing information. It works by retrieving relevant passages before the model answers, so responses are grounded in real data rather than fuzzy memory — fresher than fine-tuning, citable, and far cheaper to keep current. Get the retrieval right and you get a model that answers from your knowledge instead of guessing; get it wrong and you get fluent, confident mistakes. Either way, retrieval is where the work is.

Written by
ByteTuned Editorial Team
Senior engineers writing about building and running production AI.
Keep reading

AI agents vs chatbots: what’s actually different
A chatbot responds to a prompt and stops. An AI agent plans a goal, uses tools to carry it out, checks the result, and keeps going until the task is done. The dividing line is autonomy.

RAG vs fine-tuning: which one does your problem need?
Use RAG when the problem is missing knowledge — facts that change or that the model never saw. Use fine-tuning when the problem is behavior — a tone, format, or decision pattern. They solve different problems, and the best systems use both.

Why most AI pilots never reach production
Almost every company is running AI pilots. Very few have put one into production. The gap is not the model — it is everything around it.
Building production AI? Let’s talk.
Book a 30-minute call. We’ll map the highest-impact system to build first — and what moving that number is worth.